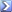
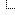
 offline
offline
Kurzer Nachtrag..
Ed hat nun die gleiche Information wie Buffet und kennt die Standard Abweichung...er optimiert nun Risiko und Return gegeneinander. Thorpe geht jetzt etwas mehr Risiko ein und ist im Durchschnitt fast so gut wie Buffet, bei einem 4tel des Risikos...und noch immer in der Mehrzahl der Szenarien(52%) besser als Buffet und im schlimmsten Fall noch immer doppelt so gut wie Buffet.
Man sieht aber auch hier: die naive Diversifikation ist, je nach Risiko Präferenz, eine nicht zu vernachlässigende Alternative.
Wer es beliebig "low risk" mag, kann im unten angehängten code auch noch das Minimum Varianz Portfolio verwenden (einfach den Term mit der Subtraktion in der loss Funktion rausnehmen)
Natürlich ist dieses Szenario sehr auf die Vorteile der Diversifikation getrimmt. Ich kenne alle Parameter,diese Parameter bleiben stabile (Stationarität), die assets sind unkorreliert...trotzdem gibt es ein Gefühl dafür, dass Diversifikation eventuell robust Vorteile bringen kann: für eure Rendite!!!
Buffet
count 1000.000000
mean 112.835756
std 41.285000
min 25.187804
25% 83.571689
50% 105.673235
75% 135.760719
max 343.162890
count 1000.000000
naive Diversifikation
mean 107.032307
std 9.779648
min 82.521911
25% 100.132379
50% 106.338482
75% 112.859044
max 140.068309
Thorpe
count 1000.000000
mean 110.015110
std 17.985399
min 67.882740
25% 97.411212
50% 108.253007
75% 119.977537
max 193.907584
Hier noch ein paar Plots zum unterschiedlichen Verlauf des Endvermögens der Szenarien...
Ed hat nun die gleiche Information wie Buffet und kennt die Standard Abweichung...er optimiert nun Risiko und Return gegeneinander. Thorpe geht jetzt etwas mehr Risiko ein und ist im Durchschnitt fast so gut wie Buffet, bei einem 4tel des Risikos...und noch immer in der Mehrzahl der Szenarien(52%) besser als Buffet und im schlimmsten Fall noch immer doppelt so gut wie Buffet.
Man sieht aber auch hier: die naive Diversifikation ist, je nach Risiko Präferenz, eine nicht zu vernachlässigende Alternative.
Wer es beliebig "low risk" mag, kann im unten angehängten code auch noch das Minimum Varianz Portfolio verwenden (einfach den Term mit der Subtraktion in der loss Funktion rausnehmen)
Natürlich ist dieses Szenario sehr auf die Vorteile der Diversifikation getrimmt. Ich kenne alle Parameter,diese Parameter bleiben stabile (Stationarität), die assets sind unkorreliert...trotzdem gibt es ein Gefühl dafür, dass Diversifikation eventuell robust Vorteile bringen kann: für eure Rendite!!!
Buffet
count 1000.000000
mean 112.835756
std 41.285000
min 25.187804
25% 83.571689
50% 105.673235
75% 135.760719
max 343.162890
count 1000.000000
naive Diversifikation
mean 107.032307
std 9.779648
min 82.521911
25% 100.132379
50% 106.338482
75% 112.859044
max 140.068309
Thorpe
count 1000.000000
mean 110.015110
std 17.985399
min 67.882740
25% 97.411212
50% 108.253007
75% 119.977537
max 193.907584
Hier noch ein paar Plots zum unterschiedlichen Verlauf des Endvermögens der Szenarien...
Code:
import numpy as np
import pandas as pd
import scipy as sc
import math
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(10)
def create_path(mu,sigma,N,S_0 = 100):
delta_t = math.sqrt(1/N)
delta = np.cumsum(np.repeat(1/N,N))
W_t = np.cumsum(delta_t*np.random.normal(0,1,N))
S_t = S_0*np.exp((mu-0.5*sigma**2)*delta + sigma*W_t)
return S_t
N = 2500
mu_1 = 0.065
sigma_1 = 0.15
mu_2 = 0.035
sigma_2 = 0.25
mu_3 = 0.01
sigma_3 = 0.075
mu_4 = 0.11
sigma_4 = 0.35
mu_5 = 0.065
sigma_5 = 0.12
mu_6 = 0.08
sigma_6 = 0.22
x0 =np.repeat(1/6,6).tolist()
loss = lambda x: 0.5*((0.15**2)*x[0]**2 + (0.25**2)*x[1]**2 + (0.075**2)*x[2]**2 + (0.35**2)*x[3]**2 + (0.12**2)*x[4]**2 +(0.22**2)*x[5]**2) - (x[0]*0.065 + x[1]*0.035 + x[2]*0.01 + x[3]*0.11 + x[4]*0.065 +x[5]*0.08)
#loss = lambda x: 0.5*((0.15**2)*x[0]**2 + (0.25**2)*x[1]**2 + (0.075**2)*x[2]**2 + (0.35**2)*x[3]**2 + (0.12**2)*x[4]**2 +(0.22**2)*x[5]**2)
cons = ({'type': 'eq', 'fun': lambda x: x[0] + x[1] + x[2] + x[3] + x[4] + x[5] -1},
{'type': 'ineq', 'fun': lambda x: x[0] -0},
{'type': 'ineq', 'fun': lambda x: x[1] -0},
{'type': 'ineq', 'fun': lambda x: x[2]-0},
{'type': 'ineq', 'fun': lambda x: x[3] -0},
{'type': 'ineq', 'fun': lambda x: x[4] -0},
{'type': 'ineq', 'fun': lambda x: x[5] -0})
#one sample path
from scipy import optimize
thorpePortfolio = optimize.minimize(fun=loss,x0=x0,constraints=cons,method="SLSQP",options={"maxiter":5000})
thorpe = np.array(thorpePortfolio.x)
dfs = []
paths = []
for trial in np.arange(1000):
df = pd.DataFrame(create_path(mu_1, sigma_1, N), columns=["a1"])
df["a2"] = create_path(mu_2, sigma_2, N)
df["a3"] = create_path(mu_3, sigma_3, N)
df["a4"] = create_path(mu_4, sigma_4, N)
df["a5"] = create_path(mu_5, sigma_5, N)
df["a6"] = create_path(mu_6, sigma_6, N)
df["naive"] = df.mean(axis=1)
df["thorpe"] = np.dot(df[["a1","a2","a3","a4","a5","a6"]].values ,thorpe)
rets = df.diff()/df
desc = rets[["a4","naive","thorpe"]].describe().loc[["mean","std","25%","75%"]].transpose()
desc["final_wealth"] = df[["a4","naive","thorpe"]].loc[N-1]
df["trial"] = trial
df["steps"] = df.index.values
dfs.append(desc)
paths.append(df)
df_final = pd.concat(dfs)
print(df_final.loc["a4"].describe()["final_wealth"].to_string())
print(df_final.loc["naive"].describe()["final_wealth"].to_string())
print(df_final.loc["thorpe"].describe()["final_wealth"].to_string())__________________
Forum-Besserwisser und Wissenschafts-Faschist
